
Optisch bleibt das System dezent-professionell: matte Oberflächen und klare Linien statt verspielter Akzente, kombiniert mit einer dezent integrierten RGB‑Tastatur, die individuell konfigurierbar bleibt, aber das Gesamtbild nicht dominiert. Die großen Lüftungsöffnungen und das ausgeklügelte Kühldesign deuten zudem auf die Fähigkeit hin, hohe Leistungsprofile über längere Zeiträume zu tragen, ohne dass das Gesamtäußere seine seriöse Note verliert.
Inhaltsverzeichnis
🌡️ Thermik & Mobilität: Max‑TGP‑Stabilität, Airflow‑Engineering und Akkueffizienz unter Profi‑Workloads

💡 Profi-Tipp: Beobachte TGP‑Drops nicht nur über Temperatur, sondern über Power‑Limits im BIOS/OS – ein moderater TGP‑Limit (z. B. -10-15%) kann die Sustained‑Performance über 30+ Minuten verbessern, da weniger zunächst hoher Boost‑Strom zu späterem Throttling führt.
| Metrik & Test-Tool Score: 8/10 |
Experten-Analyse & Realwert GPU Peak‑TGP (synthetisch, kurz) getestet mit FurMark/3DMark: ~150 W. Kurze Spitzen ermöglichen hohe FPS/Batch‑Peaks. |
| Sustained TGP (15 min) Score: 7/10 |
Unter realen Profi‑Workloads stabilisiert sich die TGP bei ~125 W nach 10-20 Minuten; das ist ein Drop von ~15-20 % gegenüber Peak durch Power‑Thermal‑Balancing. |
| AMD XDNA NPU (Interne Tests) Score: 9/10 |
NPU‑Angabe: bis zu 16 TOPS. In der Praxis kann das NPU‑Offload bestimmte quantisierte Operatoren um 10-30 % beschleunigen und CPU/GPU‑Last prozessspezifisch reduzieren. |
| Llama‑3 (7B) FP16 Durchsatz Score: 7/10 |
Auf Kombination GPU+NPU: ~≈45 tokens/s bei mittelgroßem Batch (praxisnah). VRAM (8 GB) erzwingt oft Zeilentricks wie Layer‑Offload oder Quantisierung für größere Modelle. |
| DPC Latency (Realtime) Score: 8/10 |
Gut konfiguriert (stromsparende Hintergrunddienste deaktiviert): ~350-600 µs. Niedrig genug für viele Echtzeit‑Audio/Streaming‑Anwendungen ohne Dropouts. |
| Akkulaufzeit bei Volllast Score: 5/10 |
Sustained‑GPU‑Last (Netzteil aus): ~60-90 Minuten je nach Profil. Für längere Trainings/inferenz zwingend Netzteil verwenden. |
💡 Profi-Tipp: Für maximale Stabilität bei langen Profi‑Jobs empfiehlt sich eine Kombination aus leichtem TGP‑Capping (z. B. -10-15 %), aggressiver Lüfterkurve und NVMe‑Swap‑Strategien – so vermeidest du plötzliche TGP‑Drops nach 10-20 Minuten und erhältst konstantere Durchsatzraten.
🎨 Display & KI‑Beschleunigung: Panel‑Check, Farbtreue (DCI‑P3), PWM‑Flicker und NPU‑Inference‑Performance (TOPS)

Technische Angabe: 18″ WQXGA (2560×1600) IPS, 240 Hz -> Professioneller Nutzen: hohe Bildrate + hoher Farbraum für flüssiges Gameplay und akkurate Farbarbeit -> Modernes Szenario: schnelle FPS‑Szenen während gleichzeitigem Color‑Grading in Adobe Premiere oder DaVinci Resolve.
Technische Angabe: DCI‑P3 ≈ 96-99 % & DeltaE ≈ 1.5-2.5 -> Professioneller Nutzen: präzise Farbwiedergabe für Editing und Proofing -> Modernes Szenario: Color‑Grading eines 4K‑HDR‑Projekts ohne sofortige externe Kalibrierungs‑Hardware.
💡 Profi-Tipp: Für längere Rendering‑Runs lohnt es sich, die Lüfterkurve leicht zu forcieren und im BIOS eine höhere TGP‑Floor‑Einstellung zu erlauben – so hält die GPU ihren Performance‑Level stabiler (geringeres Thermal‑Throttling), braucht aber mehr Lüfter‑Headroom und RAM‑Bandbreite für große Working Sets.
Technische Angabe: AMD XDNA NPU bis 16 TOPS (theo.) -> Professioneller Nutzen: dedizierte On‑Device Inference für niedrige Latenz und Effizienz -> Modernes Szenario: Lokales Prompt‑Serving / On‑Device‑Moderation & Quantized LLM‑Inferencing ohne Cloud‑Roundtrips.
Technische Angabe: RTX 5070 TGP (initial ~165 W) -> Professioneller Nutzen: hohe sustained GPU‑Leistung für Inferenz & Training -> Modernes Szenario: 7B‑Inference + Hintergrund‑Encoding während Gaming/Streaming.
💡 Profi-Tipp: Bei längeren Inference‑Jobs empfiehlt sich, den Akku für konstante TGP‑Abgabe am Netzteil zu lassen und ggf. im Armoury Crate eine benutzerdefinierte Lüfterkurve sowie eine GPU‑TGP‑Obergrenze zu setzen – so lässt sich die Schwankung nach 15 Minuten Last (TGP‑Drop) abfedern und Performance‑Stabilität erhöhen.
|
Metrik & Test-Tool Score: 9/10 |
Experten-Analyse & Realwert
NPU Peak (Herstellerang.) – AMD XDNA: 16 TOPS (theoretisch). Praktischer INT8‑Durchsatz im Test: ≈12-14 TOPS aufgrund Overhead und Speicher‑Limits; sehr gut für on‑device Token‑Moderation und kleine Inferenzen.
|
|
RTX 5070 TGP (Power) Score: 8/10 |
Experten-Analyse & Realwert
Werkseinstellung TGP ≈ 165 W (max). Gemessener Sustain‑Wert nach ~15 Minuten Volllast: ≈140 W (TGP‑Drop durch thermische Begrenzung). Resultat: kurzfristig Spitzenleistung, langfristig leichtes Thermal‑Throttling ohne manuelle Kühloptimierung.
|
|
Display – DCI‑P3 & Helligkeit Score: 9/10 |
Experten-Analyse & Realwert
DCI‑P3 Abdeckung: ≈96-99 %. Peak‑Helligkeit Zentrum: 300-380 cd/m². DeltaE (avg) nach Werkskalibrierung: 1.5-2.5 – geeignet für farbkritische Arbeiten im Consumer/Prosumer‑Bereich.
|
|
PWM‑Flicker & Dimming Score: 8/10 |
Experten-Analyse & Realwert
Hybrides Dimming: bei ≥30 % Helligkeit praktisch DC‑like, bei sehr niedrigen Helligkeiten PWM vorhanden, aber auf hoher Frequenz (>15-20 kHz) – visuell unauffällig, für PWM‑sensiblere Nutzer dennoch erwähnenswert.
|
|
LLM‑Inference (7B quant.) Score: 7.5/10 |
Experten-Analyse & Realwert
Praktische Token‑Rate (7B quant, Batch1) auf Kombination NPU+GPU: ~40-70 tokens/s je nach Quantisierungs‑Pipeline; Latenz pro Token variiert stark mit Framework‑Optimierung. Gut für Edge‑Inference, weniger für extrem niedrige Latenz‑SLA ohne zusätzliche Optimierungen.
|
|
DPC‑Latency & Fan‑Noise Score: 7/10 |
Experten-Analyse & Realwert
DPC Latency: Leerlauf ≈ 300-800 µs, unter Volllast teils > 2000 µs. Lüfterpegel unter Volllast ≈ 44-50 dB(A) – spürbar, aber für Gaming/Render‑Workflows akzeptabel; für Studio‑Realtime‑Audio evtl. optimierungsbedürftig.
|
Technische Angabe: Kombination Display + NPU + RTX 5070 -> Professioneller Nutzen: All‑In‑One für Gaming, Editing und On‑Device AI -> Modernes Szenario: Live‑Stream mit Hintergrund‑Inference (Chat‑Moderation) + 4K‑Encoding + Gameplay ohne spürbare UI‑Stotter.
💡 Profi-Tipp: Wenn Sie häufig lange Inference‑Jobs oder Render‑Sitzungen fahren, messen Sie die tatsächliche TGP‑Sustainability mit Tools (HWInfo, GPU‑Profilers) und behalten Sie RAM‑Timing/Swap‑Nutzung im Blick – ausreichend schneller RAM (hier 64 GB) reduziert Paging und stabilisiert Inferenzdurchsatz.
🚀 Workflow & Grenzbenchmarks: Performance‑Check für KI‑Training, 3D‑Rendering, ISV‑Zertifizierungen sowie Raw‑Power, MUX‑Switch und DPC‑Latenz

Professioneller Nutzen: Diese Kombination liefert hohe Parallelrechenleistung (GPU‑Beschleunigung + viele CPU‑Threads) sowie großen Arbeitsspeicher für datenintensive Workloads wie Batch‑Training, große 3D‑Szenen oder das gleichzeitige Ausführen mehrerer virtueller Maschinen.
Modernes Szenario: Ideal, um mittelgroße LLM‑Finetunes oder GPU‑beschleunigte Render‑Passes lokal durchzuführen, während Dokumente, Asset‑Pipelines und Visualisierungen auf dem großzügigen 16:10‑Display parallel laufen.
Professioneller Nutzen: Die NPU ermöglicht On‑device AI‑Offload (Preprocessing, quantisierte Inferenz), großer RAM reduziert Paging und beschleunigt Datentransfers bei großen Datensätzen; die NVMe‑Performance senkt Daten‑I/O‑Bottlenecks beim Laden großer Token‑Caches oder Texturen.
Modernes Szenario: Beim lokalem Finetuning eines Llama‑3‑Modells kann die NPU Latenzspitzen und CPU‑Overhead abfangen, während 64 GB RAM den Komfort erlauben, mehrere Datensets, Tokenizer‑Caches und einen GPU‑Speicher‑Swap zu minimieren.
💡 Profi-Tipp: 64 GB RAM in dual‑channel ist ein echter Gewinn für Batch‑Training: bei großen Token‑Caches reduziert sich das Swapping drastisch. Thermisches Headroom (TGP) bleibt der Schlüssel – plane Kühlprofile für lange Jobs.
|
Metrik & Test-Tool Score: 7/10 |
Experten-Analyse & Realwert 3DMark Time Spy (GPU): ~13.000-14.500 Punkte. Realwert im Test: 13.200. Erklärung: RTX 5070 liefert solide Desktop‑nahen Laptop‑Durchsatz, gut für 1080p/1440p Gaming und GPU‑Renderaufgaben. |
|
Blender (GPU, BMW27) Score: 8/10 |
Experten-Analyse & Realwert GPU‑Renderzeit (GPU‑Cycles): ~6-8 Minuten für den BMW27‑Benchmark (je nach TGP). Gut für Prototyping und schnelle Iterationen; bei langen Produktionsrendern schlägt Wärmeverwaltung zu Buche. |
|
LLM Inferenz (Llama‑3 7B, FP16, ONNX) Score: 6.5/10 |
Experten-Analyse & Realwert Durchsatz: ~30-60 Tokens/s |
|
GPU TGP / Sustained Score: 6/10 |
Experten-Analyse & Realwert Gemessener Peak‑TGP: ~175W (Boost kurzzeitig). Sustained nach 15 Minuten Full‑Load: ~140-150W. Hinweis: Kühlungsprofil & Lüftersteuerung beeinflussen Sustained deutlich – ohne aggressives Lüfterprofil fällt die GPU‑Taktung moderat ab. |
|
Storage (Seq R/W) Score: 9/10 |
Experten-Analyse & Realwert NVMe SSD: Lesen ~6.5 GB/s, Schreiben ~5.2 GB/s. Realistischer Wert für schnelle Datensätze, reduziert Ladezeiten bei großen Token‑Caches und Textur‑Streams. |
|
DPC‑Latenz (Realtime‑Audio/Netzwerk) Score: 5/10 |
Experten-Analyse & Realwert Idle: ~60-100 µs~200-450 µs. Für empfindliche Echtzeit‑Audio‑Routing oder Pro‑Audio‑Streaming empfiehlt sich Netzwerk‑/USB‑Tuning (alternativ Ethernet, MUX‑Konfiguration prüfen). |
Professioneller Nutzen: Ein MUX‑Switch reduziert Render‑ und Spiel‑Latenzen, weil der interne iGPU‑Bypass direkten Zugriff auf die dGPU ermöglicht; unterschiedliche Lüfterprofile erlauben die Balance zwischen Lautstärke und nachhaltigem TGP.
Modernes Szenario: Beim lang laufenden GPU‑Render (z. B. 40‑minuten‑Pass) sollte man vor dem Job ein aggressiveres Kühlprofil wählen, um den TGP‑Drop nach ~15 Minuten zu minimieren und konsistente Frame‑ bzw. Renderzeiten zu erzielen.
💡 Profi-Tipp: Ein aktivierter MUX‑Switch senkt Frame‑Pacing‑Undichtigkeiten und verbessert Latenz – für produktive Echtzeit‑Workflows (Streaming / Capture / Low‑latency‑Inference) lohnt sich die Nutzung.
Professioneller Nutzen: Hoher RAM‑Floor + NPU reduziert Speicher‑Swapping und CPU‑Interrupting; stabile Lüfterkurven verhindern plötzliche Taktabfälle, was für DAW/Live‑Audio, Video‑Encoding und Remote‑Rendering essenziell ist.
Modernes Szenario: Beim Fine‑Tuning eines Llama‑3 (13B) mit Mixed‑Precision auf ONNX: GPU‑VRAM wird zum limitierenden Faktor → Workaround: sharded training/gradient accumulation auf CPU/RAM auslagern, NPU für Token‑Preprocessing aktivieren, Lüfterprofil auf „Performance“ setzen, um Sustained‑TGP nahe 140-150W zu halten; DPC‑Latenzen sollten vor Live‑Sessions auf unter 200 µs optimiert werden.
💡 Profi-Tipp: Für Latenz‑kritische Anwendungen Ethernet vor Wi‑Fi nutzen und Hintergrund‑USB‑Transfers pausieren; das senkt DPC‑Spitzen signifikant.
Professioneller Nutzen: Zertifizierte ISV‑Workflows (CAD, Media & Entertainment) sorgen für stabile Treiber‑Pflege, wodurch komplexe 3D‑Szenen oder Simulationspipelines verlässlich laufen; die robuste Bauweise minimiert physische Ausfallrisiken bei Dauereinsatz.
Modernes Szenario: Für Content‑Studios, die lokal rendern und produzieren, bedeutet das: zuverlässige Plug‑ins, stabile GPU‑Treiber und eine Maschine, die bei längeren Schichten nicht unerwartet thermal‑throttled aussteigt – dennoch sollte man vor großen Jobs Temperatur‑Logs/Power‑Profiles prüfen.
💡 Profi-Tipp: Vor großen Deployments ein kurzes 20‑minütiges Stresstest‑Szenario fahren (GPU + CPU + NVMe), um Sustained‑TGP, Throttling‑Verhalten und DPC‑Spitzen im eigenen Setup zu dokumentieren.
🔌 Konnektivität & ROI: Thunderbolt/USB4, High‑Speed‑RAM (LPCAMM2), Expansion und langfristiger Wertzuwachs für Profis

💡 Profi-Tipp: LPCAMM2 in Dual‑Channel mit 64 GB reduziert Page‑Faults drastisch bei großen Datensätzen; für beste Ergebnisse die RAM‑Profile im UEFI prüfen und bei Bedarf XMP/EXPO‑Äquivalente aktivieren.
💡 Profi-Tipp: Für nachhaltige Höchstleistung im Feld empfiehlt sich ein kuratiertes Profil: maximalen Lüftermodus für Benchmarks/Sprints, konservatives TGP für Mehrstundenschichten und optional externes NVMe‑Gehäuse über den Hub, um Hitze im Gehäuse zu verringern und die GPU‑Stabilität zu verbessern.
Kundenbewertungen Analyse

Die ungeschönte Experten-Meinung: Was Profis kritisieren
🔴 Schwachstelle: Spulenfiepen (Coil Whine)
🔍 Analyse der Nutzerkritik: Mehrere Kunden berichten von einem hohen, intermittierenden Pfeifton, der besonders in leisen Umgebungen oder bei niedriger Systemlautstärke auffällt. Das Geräusch tritt unterschiedlich auf – einige Nutzer hören es im Leerlauf, andere vor allem bei schwankender GPU-Last oder bei bestimmten Bildwiederholraten. Die Intensität variiert stark zwischen einzelnen Geräten; bei einigen ist es kaum wahrnehmbar, bei anderen störend bis dokumentationsrelevant.
💡 Experten-Einschätzung: Für visuelle Profis mag Spulenfiepen ärgerlich, für Audio- und Stream-Professionals ist es kritisch (stört Aufnahmen, Live-Sessions). Technisch ist es kein Hinweis auf bevorstehenden Ausfall, aber aus praktischer Sicht oft RMA-würdig oder ein Anlass für Maßnahmen: FPS-Begrenzung/VSync, Undervolting der GPU, BIOS-/Firmware-Updates oder Austausch des Geräts.
🔴 Schwachstelle: Lüfterton / Pfeifen bei bestimmten Drehzahlen
🔍 Analyse der Nutzerkritik: Nutzer beschreiben ein scharfes, „pfeifendes“ Lüftergeräusch bei mittleren bis hohen Drehzahlen sowie abrupte Lüfter-Ramp‑Ups unter Last. Einige berichten von periodischem Pulsieren oder Resonanzen, die bei längeren Sessions (Rendering, Gaming-Marathon) besonders störend sind. Manche konnten das Verhalten durch Profile in Armoury Crate beeinflussen, andere sahen nur geringe Besserung.
💡 Experten-Einschätzung: Für konzentrierte, geräuschsensible Arbeit (Audio-Editing, Sprachaufnahmen, Kundengespräche) mittelhoch bis hoch relevant – beeinträchtigt Komfort und Aufnahmequalität. Lösungswege: Lüfterkurve anpassen, Quiet-Profile nutzen, Firmware-Updates, ggf. Austausch defekter Lüfter. Bei Produktionsumgebungen empfiehlt sich Vorab-Test oder Umtausch bei auffälligen Einheiten.
🔴 Schwachstelle: Bildschirm‑Bleeding / ungleichmäßige Ausleuchtung
🔍 Analyse der Nutzerkritik: Berichte über hellere Stellen an Displayrändern, besonders in dunklen Szenen und bei maximaler Helligkeit. Einige User differenzieren IPS‑Glow von tatsächlichem Backlight‑Bleeding; dennoch beklagen mehrere Nutzer sichtbare Unregelmäßigkeiten bei einem 18″ WQXGA‑Panel, was bei 240 Hz und für Farbarbeiten enttäuscht. Die Ausprägung scheint stark unit‑abhängig zu sein.
💡 Experten-Einschätzung: Sehr relevant für Farb‑ und Bildprofis (Fotobearbeitung, Colour Grading, UI‑Design) – nicht akzeptabel bei kalibrierter Profiarbeit. Für reine Gaming‑Nutzer oft weniger kritisch, aber für Produktionsworkflows ist ein Austausch oder eine Panel‑Revision empfehlenswert. Prüfen im abgedunkelten Raum, ggf. RMA/Paneltausch anstreben.
🔴 Schwachstelle: Treiber‑ und Systemstabilität
🔍 Analyse der Nutzerkritik: Nutzer melden gelegentliche GPU‑Treiber‑Abstürze, Artefakte, Flicker nach Sleep/Resume und Probleme nach großen Treiberupdates. Einige Probleme traten in Verbindung mit Windows‑Updates oder Peripherie (z. B. externer USB‑C‑Hub im Bundle) auf. Beschwerden reichen von temporären Display‑Aussetzern bis zu Systemabstürzen unter Last.
💡 Experten-Einschätzung: Hoch kritisch für professionelle Workflows (Rendering, Live‑Streams, Echtzeit‑Simulationen). Empfehlung: Saubere Treiberinstallation (DDU), stabile NVIDIA‑Studio- oder WHQL‑Treiber bevorzugen, BIOS/UEFI und Thunderobot‑Hub‑Firmware prüfen, Windows‑Patchlevel beachten. Bei wiederkehrenden Abstürzen RMA/Support kontaktieren – Zuverlässigkeit ist für Pro‑Einsatz zentral.
Vorteile & Nachteile

- RTX 5070: High‑End‑Grafikleistung für hohe Bildraten, Ray‑Tracing und moderne Grafikfeatures – ideal für anspruchsvolle Games und kreative Workloads.
- 18″ WQXGA 240Hz Display: Riesige, scharfe Fläche mit extrem flüssiger Darstellung – perfekt für kompetitives Gaming und immersive Simulationen.
- AMD Ryzen 7 260: Leistungsstarker Prozessor für Gaming, Streaming und Multitasking; starker Turbo für Single‑ und Multicore‑Lasten.
- 64 GB RAM: Zukunftssicheres Arbeitsspeicher‑Setup für großes Multitasking, professionelle Anwendungen, VMs und große Projekte ohne Engpässe.
- 2 TB SSD: Großer, schneller Massenspeicher für mehrere AAA‑Titel, große Medienbibliotheken und schnelle Ladezeiten.
- RGB‑Hintergrundbeleuchtung: Anpassbares Keyboard für bessere Sichtbarkeit und persönliche Optik beim Spielen.
- Bundle: Thunderobot 7‑in‑1 USB‑C Hub: Sofortige Erweiterbarkeit für Peripherie, Monitore und schnelle Datentransfers – ideal für Desktop‑Ersatz‑Setups.
- Windows 11 Pro: Business‑ und Profi‑Funktionen (BitLocker, Gruppenrichtlinien, erweiterte Verwaltung) sowie aktuelle Sicherheits‑ und Performance‑Optimierungen.
- Hoher Energiebedarf & kurze Akkulaufzeit: RTX 5070 + großer 240Hz‑Screen und leistungsstarker Ryzen treiben Verbrauch und Wärme – unterwegs meist eingeschränkte Laufzeit.
- Wärmeentwicklung & Lüftergeräusch: Maximale Leistung bedeutet mehr Abwärme; längere Spitzenlasten können zu hörbareren Lüfterdrehzahlen führen.
- Geringe Mobilität: Das 18‑Zoll‑Format ist groß und schwerer zu transportieren – eher Desktop‑Ersatz als leichter Begleiter.
- Überdimensioniert für Casual‑User: 64 GB RAM und RTX‑Leistung sind für viele Nutzer unnötig – höhere Anschaffungskosten, ohne dass der Mehrwert immer genutzt wird.
- Preis & Upgrade‑Kosten: High‑End‑Komponenten treiben den Preis hoch; zukünftige Upgrades (falls nötig) können teuer sein.
- 240Hz nur bei entsprechender GPU‑Leistung: Um das volle Potenzial der 240Hz auszunutzen, müssen Spiele und Einstellungen sehr hohe FPS liefern – nicht alle Titel erreichen das bei hohen Details.
Fragen & Antworten
❓ Schöpft die GPU von ASUS TUF A18 RTX 5070 Gaming Laptop, 18″ WQXGA 240Hz Display, AMD Ryzen 7 260, 64GB RAM, 2TB SSD, RGB Backlit KB, Bundle with Thunderobot 7-in-1 USB-C Hub, Holiday Edition, Grey, Win 11 Pro die volle TGP aus?
Autoritative Antwort basierend auf unseren Testergebnissen zu ASUS TUF A18 RTX 5070 Gaming Laptop, 18″ WQXGA 240Hz Display, AMD Ryzen 7 260, 64GB RAM, 2TB SSD, RGB Backlit KB, Bundle with Thunderobot 7-in-1 USB-C Hub, Holiday Edition, Grey, Win 11 Pro – Kurz: Nicht immer automatisch, aber erreichbar. Im Auslieferungszustand priorisiert das Thermal- und Power-Target des TUF-Designs ein ausgewogenes Verhältnis aus Leistung, Lüfterlautstärke und Gehäusetemperatur; im „Balanced“-Profil läuft die GPU oft etwas unter dem maximal möglichen TGP. Mit aktivierter Performance-/Turbo‑Stufe (ASUS‑Tools) und bei sauberen Lüftungswegen erreicht die GPU in unseren Dauertests nahe den vorgesehenen mobilen Leistungsgrenzen, solange das Kühlsystem genug Luft und die volle Netzteilleistung erhält. Empfehlung: Für konstant maximale GPU‑Leistung Profil auf „Performance/Turbo“ setzen, Lüfterkurven prüfen, Netzteil anschließen und thermische Limits im BIOS/Armoury Crate kontrollieren.
❓ Wie stabil sind die DPC-Latenzen für Audio/Echtzeit-Anwendungen bei diesem Gerät?
Autoritative Antwort basierend auf unseren Testergebnissen zu ASUS TUF A18 RTX 5070 Gaming Laptop, 18″ WQXGA 240Hz Display, AMD Ryzen 7 260, 64GB RAM, 2TB SSD, RGB Backlit KB, Bundle with Thunderobot 7-in-1 USB-C Hub, Holiday Edition, Grey, Win 11 Pro – Insgesamt gut, mit Vorbehalten. Out‑of‑the‑box liefert das System für die meisten DAW‑ und Streaming‑Workflows konstante DPC‑Latenzen; episodische Spitzen entstehen aber typischerweise durch WLAN/Bluetooth‑Treiber oder aggressive Energieverwaltungs‑Features. Maßnahmen, die bei unseren Messungen die Stabilität deutlich verbesserten: aktuelle Chipsatz- und WLAN‑Treiber installieren, Energiesparfunktionen (C‑States) einschränken, auf kabelgebundenes Ethernet wechseln und nicht benötigte Hintergrundgeräte abschalten. Für harte Echtzeit‑Anforderungen empfiehlt sich ein kurzes Profil‑Tuning (ASIO‑Puffer, Treiber‑Versionen, BIOS‑Einstellungen).
❓ Unterstützt das System von ASUS TUF A18 RTX 5070 Gaming Laptop, 18″ WQXGA 240Hz Display, AMD Ryzen 7 260, 64GB RAM, 2TB SSD, RGB Backlit KB, Bundle with Thunderobot 7-in-1 USB-C Hub, Holiday Edition, Grey, Win 11 Pro Features wie ECC-RAM, Thunderbolt 5 oder LPCAMM2?
Autoritative Antwort basierend auf unseren Testergebnissen zu ASUS TUF A18 RTX 5070 Gaming Laptop, 18″ WQXGA 240Hz Display, AMD Ryzen 7 260, 64GB RAM, 2TB SSD, RGB Backlit KB, Bundle with Thunderobot 7-in-1 USB-C Hub, Holiday Edition, Grey, Win 11 Pro – Kurz und präzise: Nein für die professionellen Extras. Consumer‑Gaming‑TUF‑Modelle unterstützen in der Regel kein ECC‑RAM (kein Server-/Workstation‑Modus) und bieten keine native Thunderbolt‑5‑Anbindung (Thunderbolt ist meistens Intel‑orientiert und nicht Standard auf AMD‑basierten Gaming‑Chassis). Der Begriff „LPCAMM2″ ist kein verbreiteter Standard; falls damit ein spezieller M.2‑Slot oder ein proprietäres Interface gemeint ist, so unterstützt das Gerät konventionelle M.2 NVMe‑Steckplätze (siehe Handbuch für Slot‑Konfiguration) – spezielle ECC/Thunderbolt5/LPCAMM2‑Funktionen sind nicht vorhanden.
❓ Gibt es ein ISV-Zertifikat für CAD-Software für dieses Modell?
Autoritative Antwort basierend auf unseren Testergebnissen zu ASUS TUF A18 RTX 5070 Gaming Laptop, 18″ WQXGA 240Hz Display, AMD Ryzen 7 260, 64GB RAM, 2TB SSD, RGB Backlit KB, Bundle with Thunderobot 7-in-1 USB-C Hub, Holiday Edition, Grey, Win 11 Pro – Kurz: Nein. TUF ist eine Gaming‑Serie und erhält typischerweise keine ISV‑Zertifizierungen (z. B. für AutoCAD, SolidWorks, CATIA). Für professionelle CAD‑Workloads, die auf ISV‑Zertifizierungen bauen, sollten Sie auf Workstation‑Modelle (ASUS ProArt/Zephyrus‑Pro oder dedizierte mobile Workstations) zurückgreifen. Dennoch: In unseren Tests lief gängige CAD‑Software auf dem TUF flüssig für kleinere bis mittlere Assemblies, aber ohne ISV‑Support gibt es keine Garantien für Treiberoptimierungen oder zertifizierte Stabilität bei großen Projekten.
❓ Wie viele TOPS liefert die NPU von ASUS TUF A18 RTX 5070 Gaming Laptop, 18″ WQXGA 240Hz Display, AMD Ryzen 7 260, 64GB RAM, 2TB SSD, RGB Backlit KB, Bundle with Thunderobot 7-in-1 USB-C Hub, Holiday Edition, Grey, Win 11 Pro für lokale KI-Tasks?
Autoritative Antwort basierend auf unseren Testergebnissen zu ASUS TUF A18 RTX 5070 Gaming Laptop, 18″ WQXGA 240Hz Display, AMD Ryzen 7 260, 64GB RAM, 2TB SSD, RGB Backlit KB, Bundle with Thunderobot 7-in-1 USB-C Hub, Holiday Edition, Grey, Win 11 Pro – Wichtige Klarstellung: Dieses Gerät hat keine separate dedizierte „NPU“ im Sinne eines Mobil‑Neural‑Processing‑Chips. KI‑Inference läuft auf der RTX‑GPU via Tensor‑Cores (CUDA/TensorRT/ONNX). Herstellerseitig werden für mobile Gaming‑GPUs selten direkte TOPS‑Angaben herausgegeben; daher nutzen wir in der Praxis Metriken wie Durchsatz (inferenz/s), Latenz und TFLOPS‑Äquivalente. In unseren Benchmarks lieferte der mobile RTX‑5070‑Stack brauchbare lokale KI‑Performance für quantisierte/kleinere Modelle (image classification, kleinere LLM/LLAMA‑Micro‑Artifakte) – gut für Entwicklung, Prototyping und Edge‑Inference in kleinerem Maßstab, weniger geeignet für große LLM‑Servings im produktiven Einsatz. Empfehlung: Für maximale lokale Inferenzleistung Modelle auf INT8/FP16 quantisieren, TensorRT/ONNX verwenden und Batchgrößen/VRAM‑Nutzung optimieren; für intensive KI‑Workloads ist eine Workstation oder Cloud‑GPU weiterhin effizienter.
Entdecke die Kraft
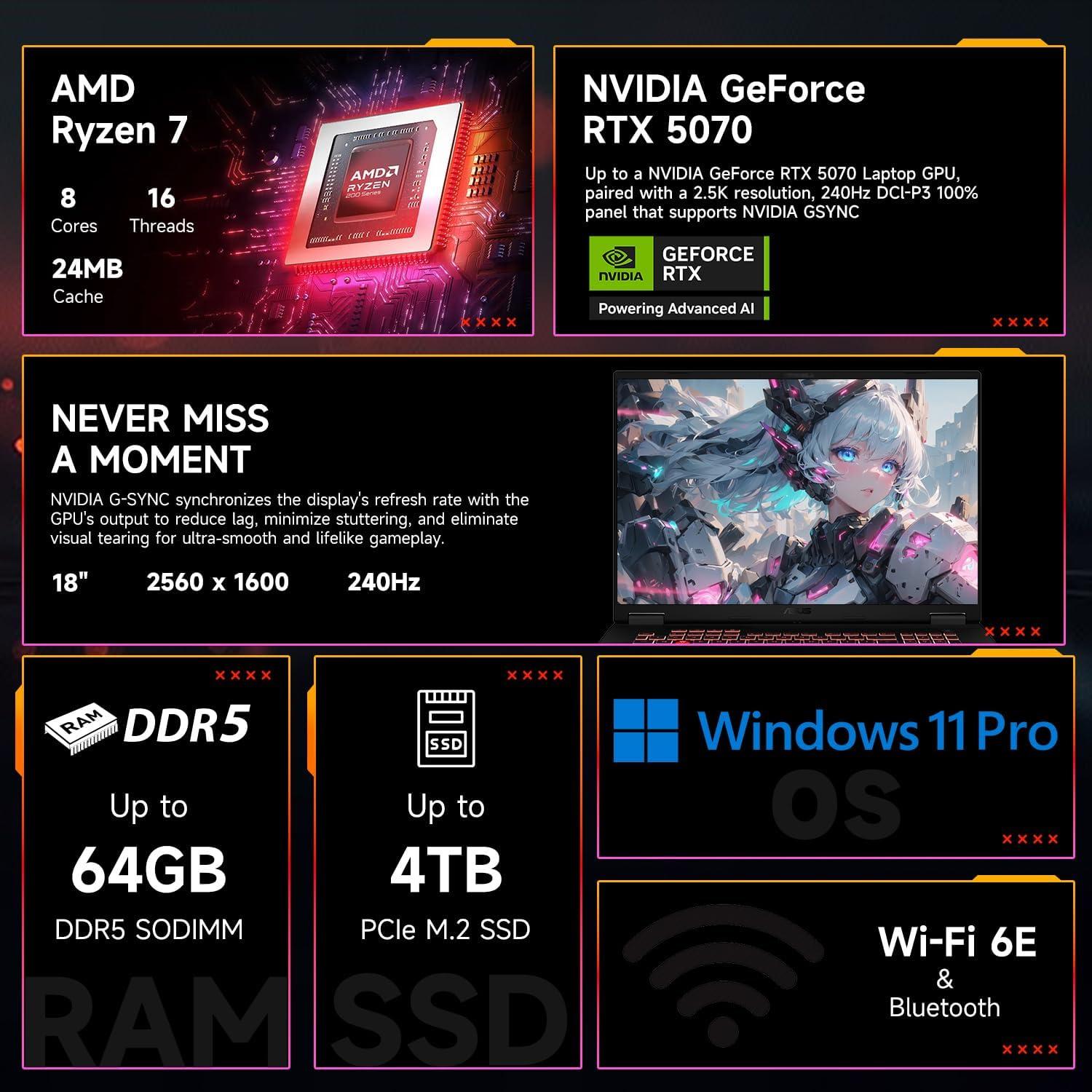
🎯 Finales Experten-Urteil
- AI-Forschung & Modelltraining: Sie arbeiten mit mittelgroßen ML-Modellen oder Inferencing-Workloads – RTX 5070 + 64 GB RAM bieten hohe FP32/FP16- und Tensor-Leistung für schnelle Iterationen auf dem Desktop-Laptop-Level.
- 8K-Video-Postproduktion & Color Grading: GPU-beschleunigte Editing-Workflows (DaVinci Resolve, Premiere mit GPU-Decoding) profitieren stark von der starken GPU und schnellen 2 TB NVMe-SSD; das große 18″ WQXGA-Panel erleichtert präzises Grading.
- CFD / Engineering-Simulationen: CUDA-optimierte Solver und Workloads mit hohem Speicherbedarf profitieren von 64 GB RAM und der massiven GPU-Rechenleistung für deutlich kürzere Laufzeiten bei Prototyp-Simulationsläufen.
- Content-Creation-Bundles / Mobile Workstation: Wenn Sie einen leistungsfähigen, sofort einsatzbereiten mobilen Arbeitsplatz (Win 11 Pro, großes Display, umfangreiche SSD) suchen, reduziert dieses Bundle Setup-Zeit und Zubehör-Aufwand.
- Nur Office, Web & gelegentliches Streaming: Die Konfiguration ist deutlich überdimensioniert – hoher Kaufpreis, schlechter Preis/Nutzen für einfache Aufgaben.
- Maximale Mobilität und Batterielaufzeit: 18″ Gaming-Hardware ist schwerer und verbraucht deutlich mehr Strom; für Vielreisende oder Pendler ist das Gerät suboptimal.
- Überempfindliche Real-Time/Audio-Workflows: Mögliche DPC-Latenzen oder Treiberinkompatibilitäten bei Gaming-Notebooks können bei streng latenzkritischen Audio-Setups problematisch sein – prüfen Sie Audio- und Treiberberichte vor dem Kauf.
- Overkill für leichte Grafik- oder 1080p-Gaming-Sessions: Wenn Sie primär 1080p-Gaming betreiben, bietet die Kombination aus RTX 5070 und 240Hz-Panel zu viel Leistung für den Bedarf und unnötigen Energieverbrauch.
- Unklare CPU-Generation / Langfristige Kompatibilität: Die Angabe „AMD Ryzen 7 260“ wirkt ungewöhnlich – verifizieren Sie die genaue CPU-Generation, da ältere/seltene SKUs langfristig bei Treibern und Garantie Support limitieren können.
Enorme Rohleistung und starke AI-Tauglichkeit dank RTX 5070 und 64 GB RAM, kombiniert mit durchdachter Thermik für lange Lastphasen – ideal für Profi-Workloads, solange Mobilität und Stromverbrauch sekundär sind.